Farris یک کاربرگ دارد که حاوی آدرس است. برخی از آدرس ها بسیار نزدیک به یک هستند، به طوری که آدرس خیابان یکسان است و فقط قسمت شماره مجموعه آدرس متفاوت است. به عنوان مثال، یک ردیف ممکن است آدرس "خیابان سیمور 85، سوئیت 101" و ردیف دیگر ممکن است دارای آدرس "خیابان سیمور 85، سوئیت 412" باشد. Farris در حال تعجب است که چگونه می تواند موارد تکراری را در لیست آدرس ها بر اساس تطابق جزئی حذف کند - فقط بر اساس آدرس خیابان و نادیده گرفتن شماره مجموعه.
ساده ترین راه حل این است که آدرس ها را به ستون های جداگانه تقسیم کنید، به طوری که شماره مجموعه در ستون خودش باشد. با دنبال کردن این مراحل می توانید این کار را انجام دهید:
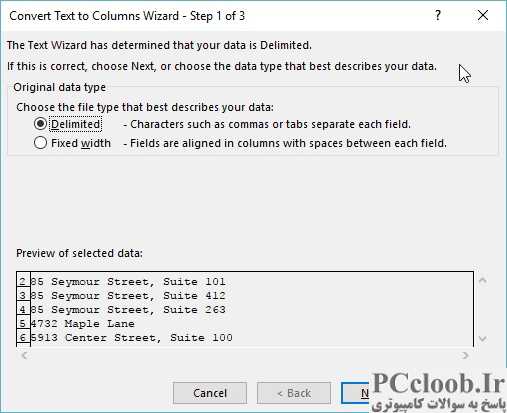
شکل 1. جادوگر تبدیل متن به ستون.
- اطمینان حاصل کنید که یک ستون خالی در سمت راست ستون آدرس وجود دارد.
- سلول های حاوی آدرس را انتخاب کنید.
- تب Data روبان را نمایش دهید.
- روی ابزار Text to Columns در گروه Data Tools کلیک کنید. اکسل جادوگر تبدیل متن به ستون را راه اندازی می کند. (شکل 1 را ببینید.)
- در مرحله اول Wizard مطمئن شوید که گزینه Delimited انتخاب شده است، سپس روی Next کلیک کنید.
- در مرحله دوم Wizard، مطمئن شوید که تیک کاما انتخاب شده است، سپس روی Next کلیک کنید.
- در مرحله سوم Wizard روی Finish کلیک کنید.
آدرس خیابان اکنون باید در ستون اصلی قرار داشته باشد و ستون خالی قبلی باید حاوی هر چیزی باشد که بعد از کاما در آدرسهای اصلی قرار دارد. به عبارت دیگر، شماره مجموعه در ستون خودش است. با دادههای شما در این شرایط، استفاده از فیلترینگ برای نمایش یا استخراج آدرسهای منحصر به فرد خیابان یک مرحله آسان است.
اگر نمیخواهید برای همیشه آدرسها را به دو ستون تقسیم کنید، میتوانید از یک فرمول برای تعیین موارد تکراری استفاده کنید. با فرض اینکه لیست آدرس مرتب شده است، می توانید از فرمولی شبیه به زیر استفاده کنید:
=IF(OR(ISERROR(FIND(",",A3)),ISERROR(FIND(",",A2))),
"",IF(LEFT(A3,FIND(",",A3))=LEFT(A2,FIND(",",A2)),
"Duplicate",""))
این فرمول فرض می کند که آدرس هایی که باید بررسی شوند در ستون A هستند و این فرمول در جایی در ردیف 3 ستون دیگری قرار می گیرد. ابتدا بررسی می کند که آیا در آدرس ردیف فعلی یا آدرس ردیف قبل کاما وجود دارد. اگر در هیچ یک از آدرس ها کاما وجود نداشته باشد، فرض می کند که امکان تکراری وجود ندارد. اگر در هر دوی آنها یک کاما وجود دارد، فرمول بخشی از آدرس ها را قبل از کاما بررسی می کند. اگر مطابقت داشته باشند، کلمه "تکراری" برگردانده می شود. اگر مطابقت نداشته باشند، هیچ چیز برگردانده نمی شود.
نتیجه کپی کردن فرمول در پایین ستون (به طوری که یک فرمول مربوط به هر آدرس باشد) این است که کلمه "Duplicate" در کنار آدرس هایی که با قسمت اول آدرس قبلی مطابقت دارند ظاهر می شود. سپس می توانید بفهمید که می خواهید با آن موارد تکراری که پیدا می شوند چه کاری انجام دهید.
گزینه دیگر استفاده از ماکرو برای تعیین موارد تکراری احتمالی است. چندین راه وجود دارد که می توان یک کلان برای تعیین موارد تکراری ابداع کرد. موردی که در اینجا نشان داده شده است به سادگی اولین کاراکترهای X یک مقدار "کلید" را در برابر یک محدوده بررسی می کند و آدرس اولین سلول منطبق را برمی گرداند.
Function NearMatch(vLookupValue, rng As Range, iNumChars)
Dim x As Integer
Dim sSub As String
Set rng = rng.Columns(1)
sSub = Left(vLookupValue, iNumChars)
For x = 1 To rng.Cells.Count
If Left(rng.Cells(x), iNumChars) = sSub Then
NearMatch = rng.Cells(x).Address
Exit Function
End If
Next
NearMatch = CVErr(xlErrNA)
End Function
به عنوان مثال، فرض کنید آدرس های شما در محدوده A2:A100 قرار دارند. در ستون B می توانید از این تابع NearMatch برای برگرداندن آدرس های تکراری احتمالی استفاده کنید. در سلول B2 فرمول زیر را وارد کنید:
=NearMatch(A2,A3:A$100,12)
اولین پارامتر برای تابع (A2) سلولی است که می خواهید به عنوان "کلید" خود استفاده کنید. 12 نویسه اول این سلول با 12 کاراکتر اول هر سلول در محدوده A3:A $100 مقایسه می شود. اگر سلولی در محدوده ای یافت شود که 12 کاراکتر اول با هم مطابقت دارند، آدرس آن سلول توسط تابع برگردانده می شود. اگر مطابقت پیدا نشد، خطای #N/A برگردانده می شود. اگر فرمول B2 را در سلول های B3:B100 به پایین کپی کنید، هر آدرس مربوطه در ستون A با تمام آدرس های زیر آن مقایسه می شود. در نهایت با لیستی از موارد تکراری احتمالی در لیست اصلی مواجه می شوید.
